Practical LLM 1 - Building Chat Application with GenAI
In the first of Practical LLM series, we will discuss how to build a basic chat based application using GenAI or Large Language Model (LLM). Like any web application, a full fledged chat application requires various components from user interface to backend service and optionally a database layer. In addition, we also need to leverage an LLM to generate chat response. Further, we need to consider limitations and constraints associated with an LLM. Lets discuss various layers needed to create a basic GenAI based application with a special focus on chat based UI.
-
Gen AI Model : The brain behind an AI based application would be the LLM Model like GPT, Claude, LLAMA etc. Depending on the need, we can use a foundation model to process inputs and generate responses. In more advanced use cases, we can train our own model or fine-tune base model with custom training data. Regardless of the type of model used, the procss to consume the model remains the same. We can pass the text prompts to the model, which in this case is prior chat messages and the model generates text response. Because of the limitation on how long the context length can be, we may have to truncate message input to include only latest chat messages.
-
Backend Service: LLM Services like OpenAI GPT and Claude expose APIs to consume the LLM model. It is possible to consume the service directly from the front end application. However, if we consume the LLM APIs from front end directly, we need to pass API key which can be exposed to public. Therefore, it is better to consume LLM APIs from the backend. One way to do it is to create an AWS lambda function to consume LLM Service.
-
Frontend App: Next we need the front end application like a web or a mobile app. Front end application will consume back end service to send user input and display the text response from the back end service.
-
LLM Cache: A cache can store previous LLM responses so identical requests don’t have to call the LLM each time. This improves latency and reduces costs of using LLM models.
-
Knowledge Base: The LLM can be augmented with external knowledge sources like databases, graphs, and corpora on specific topics. This provides it with facts and data to make responses more accurate and relevant. This technique of augmenting prompt input to the LLM is also called Retrieval Augmented Generation (RAG).
-
Moderation Tools: Moderation tools filter out toxic, incorrect, or irrelevant LLM responses before returning them to users. This could involve blocklists, sensitivity classifiers, etc.
-
Monitoring & Logging: Monitoring & Logging system is used to track system performance, usage, errors etc. This is Important for optimizing and maintaining a production LLM system.
Putting It All Together
To put everything together, we will create a basic working chat application. We will use minimal components needed, i.e. an AI model, a backend service and a front end UI application. Below is the sequence diagram of how the chat application will be put together to make an end to end working application.
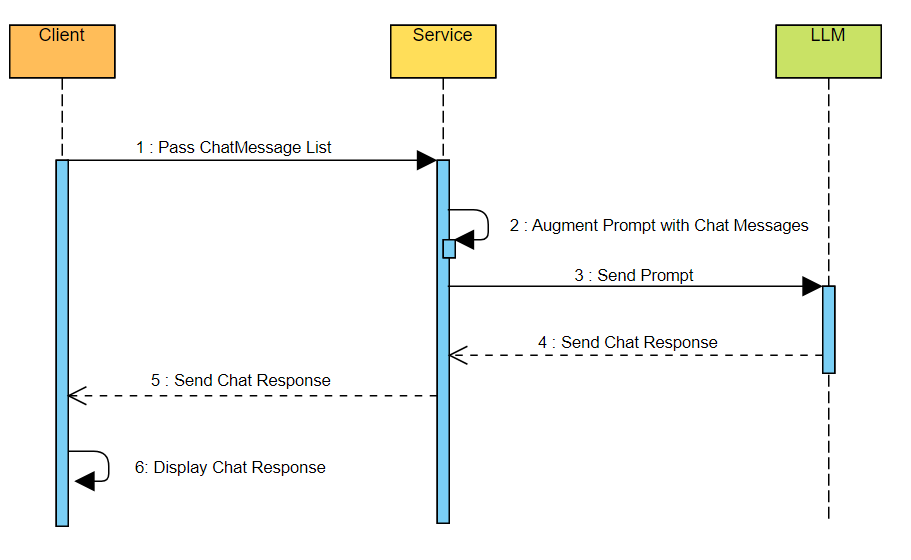
In our application, frontend will be built with React and backend with node deployed to AWS Lambda. We will configure API Gateway to expose our Lambda Service. Also, we will use Anthropic Claude Base Model available with Amazon Bedrock as our LLM service.
Now lets discuss the key code for both front end and back end pieces.
In the front end code, we can create a list of messages from prior conversation between the user and the AI service. We can then append the most recent user message and pass to the service. The service returns the response from the AI which we can append to the message list. Finally, we can update the message list in the chat UI. This process is replicated every time the user enters a new message in the UI.
What if the message list gets too long and the input will exceed the allowable context length for LLM? While we haven’t handled this scenarion in our code, one way to tackle this issue would be to trim the input message to include only the n latest messages.
Below is the code to prepare and send input and append the response to the message list.
const messagesWithUserReply = messages.concat({ id: messages.length.toString(), content: input, role: "user" });
setMessages(messagesWithUserReply);
const response = await fetch(endpoint, {
method: "POST",
body: JSON.stringify({
messages: messagesWithUserReply
})
});
const json = await response.json();
if (response.status === 200) {
const newMessages = messagesWithUserReply;
setMessages([...newMessages, { id: newMessages.length.toString(), content: json.output, role: "assistant" }]);
}
Full source code for UI is available here. https://github.com/sekharkafle/chatui
In the backend, we need to modify the chat messages received by front end in the format expected by LLM service. Below is the code snippet that can be used to format the message list into a String with a series of Human and Assistant texts as required by Anthropic Claude LLM.
const formatMessages = (chatHistory: ChatMessage[]) => {
const formattedDialogueTurns = chatHistory.map((message) => {
if (message.role === "user") {
return `Human: ${message.content}`;
} else if (message.role === "assistant") {
return `Assistant: ${message.content}`;
} else {
return `${message.role}: ${message.content}`;
}
});
return formattedDialogueTurns.join("\n");
};
Once the input text is in the correct format, we are all set to send the request to Claude foundation model in Bedrock using AWS Javascript SDK:
const bedrock = new BedrockRuntimeClient({
serviceId: 'bedrock',
region: 'us-east-1',
});
const result = await bedrock.send(
new InvokeModelCommand({
modelId: 'anthropic.claude-v2',
contentType: 'application/json',
accept: '*/*',
body: JSON.stringify({
prompt,
max_tokens_to_sample: 2000,
// Temperature (1-0) is how 'creative' the LLM should be in its response
// 1: deterministic, prone to repeating
// 0: creative, prone to hallucinations
temperature: 1,
top_k: 250,
top_p: 0.99,
// This tells the model when to stop its response. LLMs
// generally have a chat-like string of Human and Assistant message
// This says stop when the Assistant (Claude) is done and expects
// the human to respond
stop_sequences: ['\n\nHuman:'],
anthropic_version: 'bedrock-2023-05-31'
})
})
);
// The response is a Uint8Array of a stringified JSON blob
// so you need to first decode the Uint8Array to a string
// then parse the string.
return new TextDecoder().decode(result.body);
Full source code for Lambda Service is available here. https://github.com/sekharkafle/chatlambda
After we configure API gateway with the Lambda for UI to send the request, we are all done to test the application.
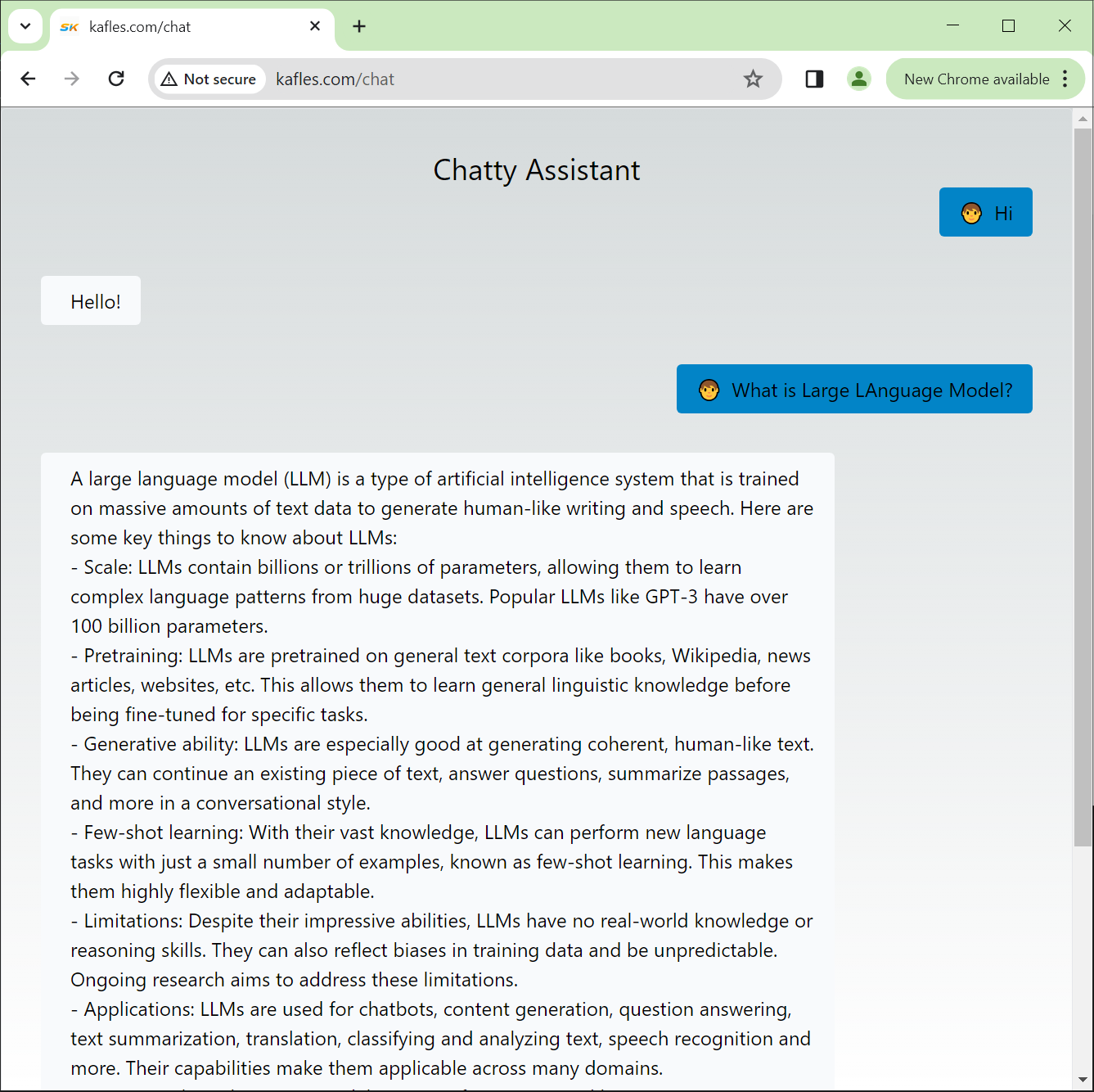
Happy Chatting!!!