Practical LLM 4 - Semantic Search
In the fourth installment of Practical LLM series(See Part 1, Part 2, Part 3), we will discuss how to build an app to perform semantic search. With a traditional database, we can perform query matching an input string using SQL.
Using LLM and Vector Database, we can go a step further and perform semantic search, i.e. find text with similar meaning. To enable this functionality, first we need to create vector embedding using LLM and load vector data in a Vector Database. Once the data is available in Vector Database, in real time we can perform query by first creating embedding vector of the input text and run similarity query in the database.
For this demo app, we will build a use case to perform semantic search for Standard Industrial Classification (SIC) database. The CSV file used for this demo is downloaded from here. We will be using PineCone as vector database for storing and searching feature and OpenAI LLM to create embeddings.
Below diagram shows data load process implemented fo this demo app:

Architecture for the search process is illustrated below:

Load Data to Vector Database
CSV data downloaded from BLS contains SIC Industry code and Title columns.
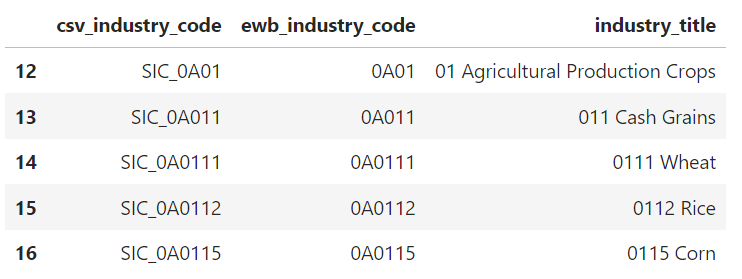
We will use text from title column and create embedding vector of the text using OpenAI.
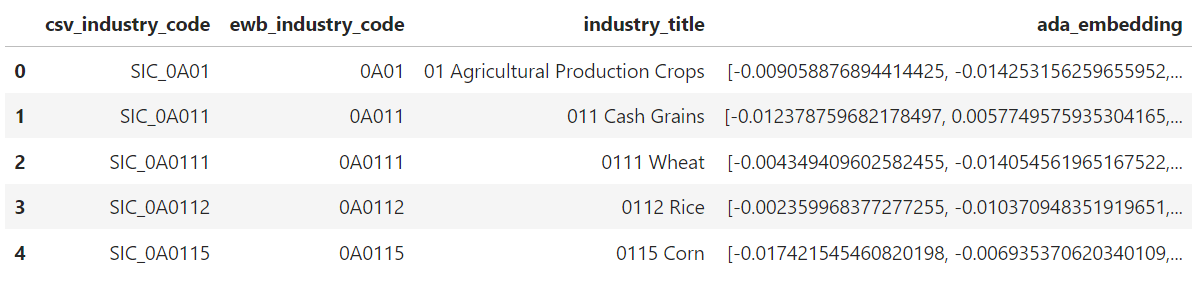
We add embedding data to the dataframe and load the text and vector data to the PineCone database.
Source code is available here: https://github.com/sekharkafle/semantic-search/blob/main/python/sic-embedding.ipynb
Query Application
Our front end code is quite simple. It simply allows user to enter search text. The code then sends the text to the service for semantci query. Relevant code is shown below:
const onSubmit = async (e: React.FormEvent<HTMLFormElement>) => {
e.preventDefault()
if (!query) return
setIsLoading(true);
setResult([]);
try {
const data = {question:query};
const res = await fetch(serviceUrl, {
method: 'POST',
body: JSON.stringify(data)
})
// handle the error
if (!res.ok) throw new Error(await res.text())
setIsLoading(false);
const resJ = await res.json();
setResult(resJ.matches);
} catch (e: any) {
// Handle errors here
console.error(e)
setIsLoading(false);
}
}
Next lets discuss the backend. The backend code creates vector embedding for input text using OpenAI. The embedding vector is passed to Pinecone database to perform semantically matching terms which is relayed back to the client. Relevant code is given below:
const pinecone = new Pinecone();
// Target the index
const indexName = getEnv("PINECONE_INDEX");
const index = pinecone.index(indexName);
const openai = new OpenAI({
apiKey: getEnv("OPENAI_KEY"),
});
const embedding = await openai.embeddings.create({
model: "text-embedding-ada-002",
input:body.question,
encoding_format: "float",
});
const topK: number = 15;
// Query the index using the query embedding
const results = await index.query({
vector: embedding.data[0].embedding,
topK,
includeMetadata: true,
includeValues: false,
});
results.matches?.map((match) => ({
text: match.metadata?.text,
score: match.score,
}))
return {
statusCode: 200,
body: JSON.stringify(results),
};
JSON input payload to the service is given below:
{"question":"wine"}
Response includes matching terms based on the descending score of cosine similarity with the input text. In the response, we also include the SIC title text loaded as a metadata field in the vector database.
{
"matches": [
{
"id": "264",
"score": 0.853567243,
"values": [],
"metadata": {
"text": "2084 Wines, brandy, and brandy spirits"
}
},
{
"id": "1133",
"score": 0.844626307,
"values": [],
"metadata": {
"text": "518 Beer, Wine, and Distilled Beverages"
}
},
{
"id": "1135",
"score": 0.842519879,
"values": [],
"metadata": {
"text": "5182 Wine and distilled beverages"
}
},
{
"id": "17",
"score": 0.829657078,
"values": [],
"metadata": {
"text": "0172 Grapes"
}
},
{
"id": "261",
"score": 0.82220459,
"values": [],
"metadata": {
"text": "208 Beverages"
}
},
{
"id": "265",
"score": 0.819555402,
"values": [],
"metadata": {
"text": "2085 Distilled and blended liquors"
}
},
{
"id": "1134",
"score": 0.815718412,
"values": [],
"metadata": {
"text": "5181 Beer and ale"
}
},
{
"id": "1239",
"score": 0.81060648,
"values": [],
"metadata": {
"text": "5921 Liquor stores"
}
},
{
"id": "1238",
"score": 0.80651921,
"values": [],
"metadata": {
"text": "592 Liquor Stores"
}
},
{
"id": "266",
"score": 0.804716706,
"values": [],
"metadata": {
"text": "2086 Bottled and canned soft drinks"
}
},
{
"id": "262",
"score": 0.804617941,
"values": [],
"metadata": {
"text": "2082 Malt beverages"
}
},
{
"id": "283",
"score": 0.803304434,
"values": [],
"metadata": {
"text": "214 Tobacco Stemming and Redrying"
}
},
{
"id": "1234",
"score": 0.800491869,
"values": [],
"metadata": {
"text": "5813 Drinking places"
}
},
{
"id": "263",
"score": 0.799584866,
"values": [],
"metadata": {
"text": "2083 Malt"
}
},
{
"id": "215",
"score": 0.794926107,
"values": [],
"metadata": {
"text": "201 Meat Products"
}
}
],
"namespace": ""
}
Full source code for the demo application is available here. https://github.com/sekharkafle/semantic-search
With both back end and front end code ready to go, we are all set to test the web app:
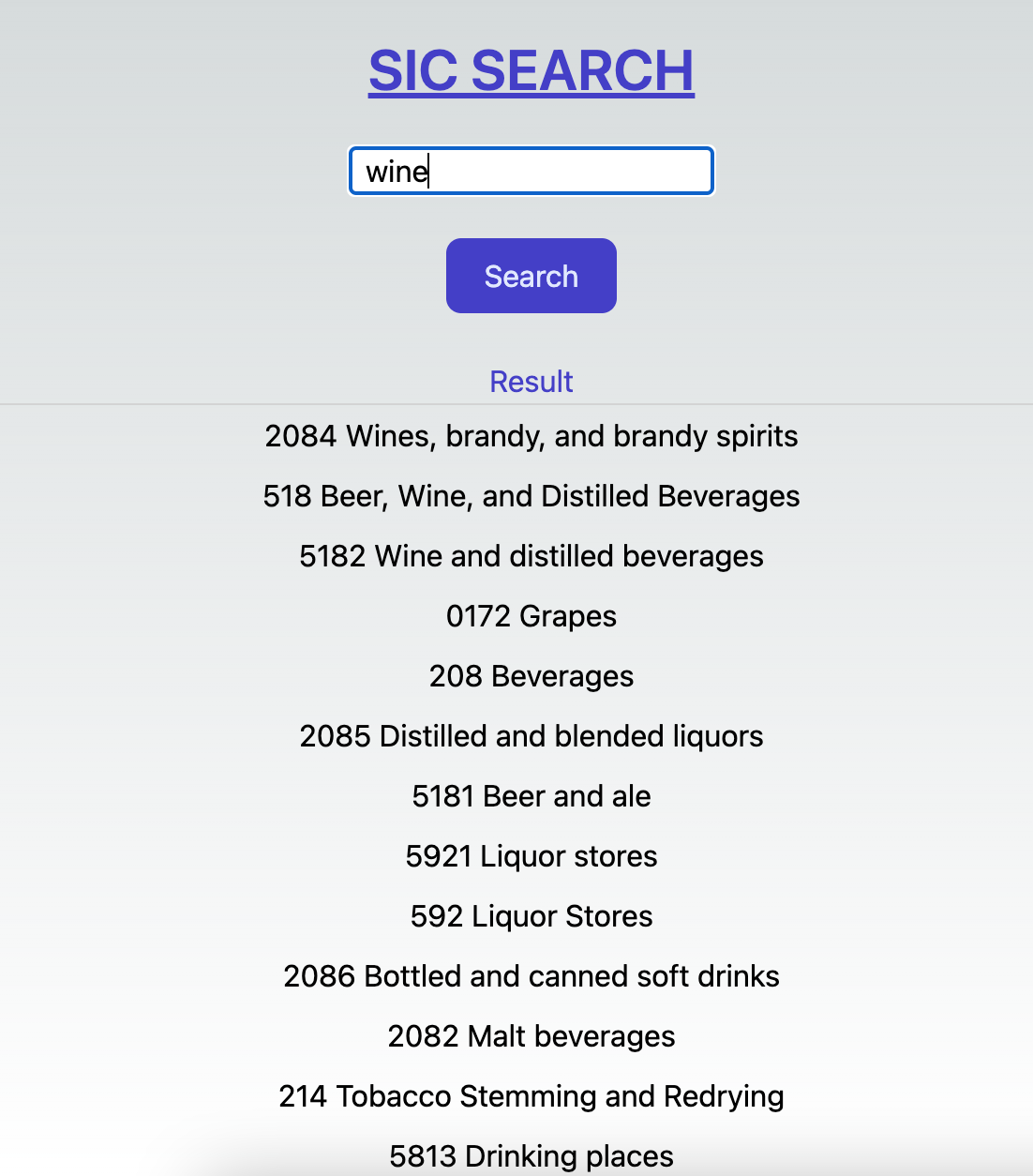
Happy Searching!!!